Robots.txt’nin Web Sitelerindeki Anlaşılması ve İşlevleri
Robot Hariç Tutma Protokolü (REP) veya Robots.txt Arama Motorları için tarama kurallarını içeren bir dosyadır. Genellikle robots.txt işlevi, indekslenmesini veya arama motorları tarafından takip edilmesini istemediğiniz sayfaları engellemek için kullanılır. Ya Google ve benzerlerinin web sitesini taramasına izin verir ya da vermez.
Web sitenizin kök klasöründe bulunur. .htaccess ve diğer alt klasörlerle birlikte. Son birkaç yılda Robots.txt, hem WordPress, Blogger, Joomla hem de diğer web sitesi kullanıcıları için oldukça popüler hale geldi. Çünkü bu özellik geliştiricilerin web sitelerinin gizliliğini yönetmelerini kolaylaştırıyor.
Bilmek istiyorum Bir web sitesinde robots.txt’nin tanımı ve işlevi?
Hangi Arama Motorları Robots.txt’yi Destekliyor?
Aşağıdaki tabloya bakalım!
| Robotların değeri | Yahoo! | MSN/Canlı/Bing | Sormak | |
|---|---|---|---|---|
| dizin | Evet | Evet | Evet | Evet |
| noindeks | Evet | Evet | Evet | Evet |
| hiçbiri | Evet | Şüphe | Şüphe | Evet |
| takip etmek | Evet | Şüphe | Şüphe | Evet |
| takip etme | Evet | Evet | Evet | Evet |
| arşiv | Evet | Evet | Evet | Evet |
| küçük parça | Evet | HAYIR | HAYIR | HAYIR |
| noodp | Evet | Evet | Evet | HAYIR |
| noydır | Faydası yok | Evet | Faydası yok | Faydası yok |
Robots.txt Komut İşlevi
- indeks: Söz konusu sayfanın aramalarda görülmesine ve dizine eklenmesine izin verilmesi
- noindeks: Arama motorlarının söz konusu sayfayı dizine eklemesine izin vermez
- noimageindex: Görsellerin arama motorları tarafından indekslenmesine izin vermez. Bu Instagram tarafından kullanılıyor
- takip etmek : Varsayılan olarak tüm sayfalarda takip komutu bulunur. Böylece her sayfa arama robotları tarafından takip edilir
- takip etme : Takip etmenin tersi. Arama robotlarının bağlantılara erişimini engeller
- arşiv: Arama motorlarının söz konusu sayfanın yedek verilerini sağlamasına izin vermez
- nocache: Tıpkı noarchive gibi, yalnızca önbellek bölümü için özel olarak
- küçük parça: Arama motorlarının söz konusu sayfadaki parçalanmış cümleleri görüntülemesine izin vermez
- noodp: Arama motorlarının DMOZ’daki sayfa açıklamalarını kullanmasına izin vermez
- hayırdır: Özel siparişler Yahoo! dizin
- hiçbiri : bu en sağlam komuttur. Bu, arama robotlarının herhangi bir şey yapmasının yasak olduğu anlamına gelir
- İzin verilmiyor : Arama motorlarına izin vermeme komutu
Şunlar da hoşunuza gidebilir
Doğru Robots.txt Dosyası Örneği
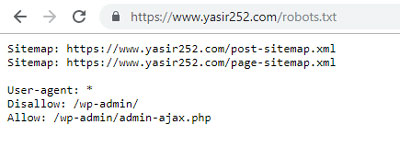
Robots.txt dosyasını bir web sitesinde görüntülemek için web sitesi URL’sine erişmeniz ve onu /robots.txt ile takip etmeniz yeterlidir. Örnek : Yoast Robotları veya NeilPatel Robotları Robots.txt dosyasının varsayılan görünümü aşağı yukarı şu şekildedir:
User-agent: * Disallow: /ebooks/*.pdf User-agent: Googlebot-Image Disallow: /images/
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Yukarıdaki iki koddan farklı özelliklere sahiptirler. Özellikle ikinci paragraf kodu için WordPress tarafından oluşturulan varsayılan robots txt’dir. Ayrıntılar için aşağıdaki açıklamaya bakın.
- Kullanıcı aracısı: * — Her türlü Arama Motoru Robotunu bildirin
- İzin verme: /ebooks/*.pdf — Her tür robotun tüm URL’lere erişmesini yasaklar
- e-kitaplar ve PDF dosyaları
- Kullanıcı aracısı: Googlebot-Resim — Googlebot görsellerinin görsellere erişmemesini bildirir
- İzin verme: /images/ — Google Bot Image’ın /images/url’ye erişmesine izin vermeyin
İzin verme: /wp-admin/
— Google Bot Görselinin /wp-admin/ url’ye erişmesine izin vermeyin
Robots.txt dosyasında site haritası yazmak gerekli midir?
Aslında teoride Site Haritasını Robots.txt dosyasına yazmak doğrudur. Ama şu anda bunun pek kullanışlı olduğunu düşünmüyorum. Bunun nedeni, Google Search Console veya Bing Web Yöneticisi Araçları’nda hâlâ bir hesap oluşturmamızın gerekli olmasıdır.